Java面试小结(三)
Java面试小结(三)
关于JDBC、Mybatis、网络基础,JavaWeb,参考博客Review-Day10
JDBC6大编程步骤
加载驱动 - 加载驱动实现类 - Driver
获取连接 - 和db进行连接 - DriverManager
获取语句对象Statement
- 写sql语句
- 由语句对象将sql发送到mysql-server,如果执行的是DQL,还需要进行结果集处理,执行第4步
处理结果集 - 通过光标来获取表中的数据 - ResultSet
关闭对象-ResultSet,Statement,Connection
SQL注入
负责发送sql语句的对象 - Statement语句对象 - 引发sql注入问题 - 是因为参数硬拼接到了sql语句中
传入非法的参数
sql注入的场景:
username是外部传过来的参数.该参数直接会被拼接到sql语句中.
rs = st.executeQuery(sql);
1 | public User getByUsername(String username) { |
PrepareStatement和Statement区别
- PreparedStatement继承自Statement,都是接口
- Statement适用于运行静态 SQL 语句[参数直接硬拼接到sql语句]。 Statement 接口不接受参数。
- **PrepareStatement计划多次使用同一条 SQL 语句[适合执行同构的sql]**, PreparedStatement接口运行时接受输入的参数。
- PrepareStatement有效防止sql注入
- PreparedStatement会预编译SQL语句,Statement每次都会解析/编译SQL
- PreparedStatement的效率 比 Statement 的效率高
连接池的工作原理
数据库连接池的基本思想就是为数据库连接 建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去
连接池的工作原理主要由三部分组成,分别为连接池的建立、连接池中连接的使用管理、连接池的关闭。
连接池的创建
一般在系统初始化时,连接池会根据系统配置建立,并在池中创建了几个连接对象,以便使用时能从连接池中获取。
连接池中的连接不能随意创建和关闭,这样避免了连接随意建立和关闭造成的系统开销。Java中提供了很多容器类可以方便的构建连接池,例如Vector[线程安全的类]、Stack等。连接池连接的使用管理
连接池管理策略是连接池机制的核心,连接池内连接的分配和释放对系统的性能有很大的影响。其管理策略是:
当客户端·请求数据库连接时,首先查看连接池中是否有空闲连接,如果存在空闲连接,则将连接分配给客户端使用;如果没有空闲连接,则查看当前所开的连接数是否已经达到最大连接数,如果没达到就重新创建一个连接给请求的客户端;如果达到就按设定的最大等待时间进行等待,如果超出最大等待时间,则抛出异常给客户端。 当客户端释放数据库连接时,先判断该连接的引用次数是否超过了规定值,如果超过就从连接池中删除该连接,否则保留为其他客户服务。该策略保证了数据库连接的有效复用,避免频繁的建立、释放连接锁带来的系统资源开销。连接池的关闭
当应用程序退出时,关闭连接池中所有的连接,释放连接池相关的资源,该过程正好与创建相反
ORM思想(对象关系映射)
表和实体类息息相关
Mybatis(半自动ORM框架)和hibernate(全自动ORM框架)区别
- Mybatis 和hibernate不同,它不完全是一个ORM框架,因为MyBatis需要程序员自己编写Sql语句。
- Mybatis 直接编写原生态sql,可以严格控制sql执行性能,灵活度高,非常适合对关系数据模型要求不高的软件开发,因为这类软件需求变化频繁, -但需求变化要求迅速输出成果。但是灵活的前提是mybatis无法做到数据库无关性,如果需要实现支持多种数据库的软件,则需要自定义多套sql映射文件,工作量大。
- Hibernate 对象/关系映射能力强,数据库无关性好,对于关系模型要求高的软件,如果用hibernate 开发可以节省很多代码,提高效率。
Mybatis(面对简单的封装,自动封装结果集)和JDBC(手动封装结果集)区别
Mybatis免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作.
复杂的查询那么仍然是需要手动进行映射的[列-属性]
${ }和#{ }区别
#{}是预编译处理, ${}是字符串替换。
Mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值;
Mybatis在处理${}时,就是把${}替换成变量的值。
使用#{}可以有效的防止SQL注入,提高系统安全性
resultType和resultMap区别
resultType
只有select标签才需要指定resultType属性
自动映射
mybatis什么时候才能够实现自动映射的效果 - 一定是查询出来的列名和实体类属性名高度保持一致
或者出来的列名是一个合法的匈牙利命名 - 实体类属性的小驼峰.
resultMap
- 当查询的列值不能自动映射/绑定实体类的属性的时候,需要通过resultMap来进行一一绑定.
selectOne和selectList区别
selectOne - 负责加载唯一的一条数据 - 返回的是一个单个对象
selectList - 负责加载多条数据,返回一个集合
如果在必须使用selectList,不小心使用到了selectOne.那么就会抛出异常
延迟加载
MyBatis中的延迟加载,也称为懒加载,是指在进行表的关联查询时,按照设置延迟规则推迟对关联对象的select查询。例如在进行一对多查询的时候,只查询出一方,当程序中需要多方的数据时,mybatis再发出sql语句进行查询,这样子延迟加载就可以的减少数据库压力。MyBatis 的延迟加载只是对关联对象的查询有迟延设置,对于主加载对象都是直接执行查询语句的。
一级缓存和二级缓存
一级缓存
mybatis中是自动开启一级缓存的.
SqlSession = Connection[Jdbc中的一次连接] + Cache[默认开启的就是一级缓存]
一级缓存是SqlSession级别的.
- 优先到一级缓存中去查询是否存在这个实体对象.如果有直接返回.否则才会和db进行交互
- 目的好处 - 为了提高查询效率的
二级缓存
mybatis并没有自动开启二级缓存,手动配置启动二级缓存
- 优先从一级缓存中去查找是否存在对象,如果不存在执行2,存在,直接返回了
- 再到二级缓存中去查找是否存在对象.如果不存在,则会和db进行交互
- 将对象散列的属性数据放一份到二级缓存.将整个实体对象[整体]放入到一级缓存中.
SqlSessionFactoryBuilder,SqlSessionFactory和SqlSession == Connection + Cache(一级缓存)
SqlSessionFactoryBuilder
仅仅只会使用到一次.
SqlSessionFactory build(InputStream in);
功能:读取xml的字节输入流来构建一个重量级的对象SqlSessionFactory - 相当于jdbc数据源对象[BasicDataSource].
SqlSessionFactory
重量级的对象 - 不能随意创建多个或者随意销毁 - 耗时间 - 占内存 - 单例
一旦被创建就应该在应用的运行期间一直存在,没有任何理由丢弃它或重新创建另一个实例
SqlSession openSession();//获取Session对象
SqlSession
作用:负责和db进行CRUD操作.
与db进行一次会话 - 一次连接.相当于JDBC中的Connection对象.但是比jdbc多出缓存的功能.
SqlSession=Connection[db连接] + Cache[默认的一级缓存];
SqlSession 的实例不是线程安全的,因此是不能被共享的.每个线程都应该有它自己的 SqlSession 实例.
session应该是一个局部变量
回顾java知识点
当线程执行到方法的时候,就会在本地开辟一块区域 - 线程栈[独占的]
association和collection区别(Mybatis加载一/多的区别)
- 关联-association
- 集合-collection
association是用于一对一和多对一,而collection是用于一对多的关系
写出几个常见的SQL标签/动态SQL
循环容器的标签forEach
concat模糊查询
choose (when, otherwise)标签
choose标签是按顺序判断其内部when标签中的test条件出否成立,如果有一个成立,则 choose 结束。当 choose 中所有 when 的条件都不满则时,则执行 otherwise 中的sql。类似于Java 的 switch 语句,choose 为 switch,when 为 case,otherwise 则为 default。selectKey 标签
if标签
if + where 的条件判断
if + set实现修改语句
if + trim代替where/set标签
Mybatis分页插件
PageHelper方法使用了静态的ThreadLocal参数,分页参数和线程是绑定的。内部流程是ThreadLocal中设置了分页参数(pageIndex,pageSize),之后在查询执行的时候,获取当线程中的分页参数,执行查询的时候通过拦截器在sql语句中添加分页参数,之后实现分页查询,查询结束后在 finally 语句中清除ThreadLocal中的查询参数
PageHelper首先将前端传递的参数保存到page这个对象中,接着将page的副本存放入ThreadLoacl中,这样可以保证分页的时候,参数互不影响,接着利用了mybatis提供的拦截器,取得ThreadLocal的值,重新拼装分页SQL,完成分页。
Servlet生命周期
init,service[doGet,doPost],destroy方法
第一阶段 - Servlet何时被实例化
如果配置了0
如果配置了0或者正数,意味着启动tomcat的时候,就会立即初始化该servlet实例,并且利用该实例立即去调用init方法.
如果值一样,根据上下的配置顺序.如果值不一样.数值越小,优先级越高.
如果没有配置
当请求第一次到达的时候,tomcat容器会初始化该servlet的实例.然后利用该实例立即去调用init方法
init方法仅仅只会执行1次.第二阶段
来自于client端的请求永远是永远是先到达service方法.如果本servlet中没有重写service方法
那么会自动进入到父类HttpServlet中的service方法,根据请求的方式来决定调用doGet方法还是doPost方法.
再在重写之后的doGet方法或者doPost方法中来处理请求和响应.第三阶段
当我们关闭tomcat的时候,会调用destroy方法.
post和get区别
(1).get请求一般用于获取数据,post请求一般用于需要发数据到后台时使用
(2).get请求的参数,会放在url上,所以安全性,隐私性会比较差,post请求的参数会放在request.body中,比较的安全
(3).get请求不受到刷新,回退的影响,post请求则会在网页回退或者刷新后,重新进行发送
(4).get请求会被缓存,post请求不会被缓存
(5).get请求会被记录在浏览器的历史记录中,post请求则不会被记录
(6).get请求可以被收藏为标签,post不能被收藏为标签
(7).get请求只能进行url编码,post请求则支持多种编码
(8).get请求通常通过url地址栏请求,post通常通过表单发送数据请求
(9). post请求url长度理论上没有限制,get请求有限制[不同的浏览器不一样]
如何处理中文乱码
1 | req.setCharacterEncoding("utf-8"); |
转发/重定向
转发
- 转发发生在服务器端的跳转
- 共享request作用域中的数据
- 地址栏不变
重定向
- 重定向发生在客户端的跳转
- 至少2次请求,不能获取request作用域中的数据
- 地址栏是会发生变化的
- 可以重定向到其他站点
Cookie和session
- cookie数据存放在客户的浏览器上,session数据放在服务器上.
- cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗考虑到安全应当使用session。
- 设置cookie时间可以使cookie过期。但是使用session-destory(),我们将会销毁会话。
- session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能考虑到减轻服务器性能方面,应当使用cookie。
- 单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。(Session对象没有对存储的数据量的限制,其中可以保存更为复杂的数据类型)
注意:
session很容易失效,用户体验很差;
虽然cookie不安全,但是可以加密 ;
cookie也分为永久和暂时存在的;
浏览器 有禁止cookie功能 ,但一般用户都不会设置;
一定要设置失效时间,要不然浏览器关闭就消失了;
例如:
记住密码功能就是使用永久cookie写在客户端电脑,下次登录时,自动将cookie信息附加发送给服务端。
application是全局性信息,是所有用户共享的信息,如可以记录有多少用户现在登录过本网站,并把该信息展示个所有用户。
两者最大的区别在于生存周期,一个是IE启动到IE关闭.(浏览器页面一关 ,session就消失了),一个是预先设置的生存周期,或永久的保存于本地的文件。(cookie)
Session信息是存放在server端,但session id是存放在client cookie的,当然php的session存放方法是多样化的,这样就算禁用cookie一样可以跟踪
Cookie是完全保持在客户端的如:IE firefox 当客户端禁止cookie时将不能再使用
Cookie如何管理session
诞生背景:session为什么要进行管理?
原因:通过http协议发送的请求,http协议无状态的协议 - server不能够判断后续的多次请求是来自于同一个客户端[server本身不标识客户端.]
- 何时才会创建session空间
1-1. 当后端代码中第一次出现req.getSession();
1-2. 第一次访问jsp文件,只要设置成false,就不会创建session空间.
1 | <%@ page contentType="text/html;charset=UTF-8" language="java" session="true" %> |
当第一次请求到达req.getSession();的时候,tomcat服务器会创建一个Session空间,并且给这个空间分配一个唯一的id
接着创建了cookie,这个cookie中存放了这个空间的id,并且通过响应头信息将这个cookie发送到client端,并且保存在client后续的请求会带上存储sessionid的cookie一起发送到server端.由tomcat解析cookie中的session空间的id,然后将这个client联系到这个client对应的session空间
Http和Https
- HTTP 明文传输,数据都是未加密的,安全性较差,HTTPS(SSL+HTTP) 数据传输过程是加密的,安全性较好。
- 使用 HTTPS 协议需要到 CA(Certificate Authority,数字证书认证机构) 申请证书,一般免费证书较少,因而需要一定费用。证书颁发机构如:Symantec、Comodo、GoDaddy 和 GlobalSign 等。
- HTTP 页面响应速度比 HTTPS 快,主要是因为 HTTP 使用 TCP 三次握手建立连接,客户端和服务器需要交换 3 个包,而 HTTPS除了 TCP 的三个包,还要加上 ssl 握手需要的 9 个包,所以一共是 12 个包。
- http 和 https 使用的是完全不同的连接方式,用的端口也不一样,前者是 80,后者是 443。
- HTTPS 其实就是建构在 SSL/TLS 之上的 HTTP 协议,所以,要比较 HTTPS 比 HTTP 要更耗费服务器资源。
TCP(三次握手)
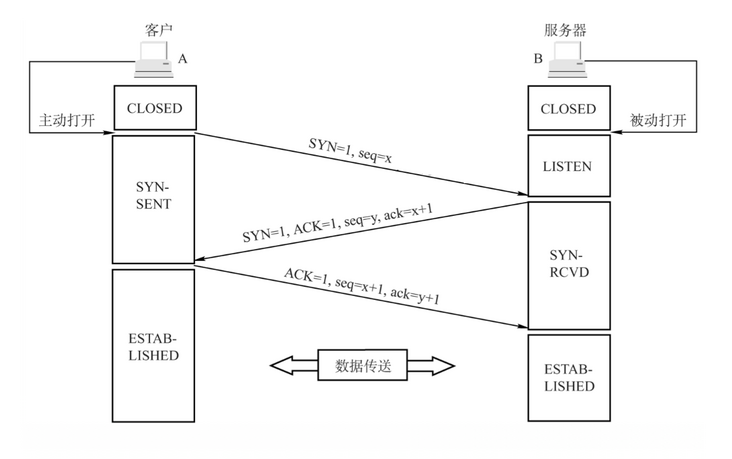
SYN:连接请求/接收 报文段 - 同步位
seq:发送的第一个字节的序号
ACK:确认报文段
ack:确认号。希望收到的下一个数据的第一个字节的序号
client和server一开始都是出于close状态
client自己想要建立请求 - 主动打开,server端被动打开的,然后server进入到listen监听状态.
(1)首先客户端向服务器端发送一段TCP报文,其中:
标记位为SYN,表示“请求建立新连接”;序号为Seq=X;随后客户端进入SYN-SENT阶段。(2)服务器端接收到来自客户端的TCP报文之后,结束LISTEN阶段。并返回一段TCP报文,其中:
标记位为SYN和ACK,表示“确认客户端的报文Seq序号有效,服务器能正常接收客户端发送的数据,并同意创建新连接”(即告诉客户端,服务器收到了你的数据);序号为Seq=y;确认号为Ack=x+1,表示收到客户端的序号Seq并将其值加1作为自己确认号Ack的值;随后服务器端进入SYN-RCVD阶段。(3)客户端接收到来自服务器端的确认收到数据的TCP报文之后,明确了从客户端到服务器的数据传输是正常的,结束SYN-SENT阶段。并返回最后一段TCP报文。其中:
标记位为ACK,表示“确认收到服务器端同意连接的信号”(即告诉服务器,我知道你收到我发的数据了);序号为Seq=x+1,表示收到服务器端的确认号Ack,并将其值作为自己的序号值;确认号为Ack=y+1,表示收到服务器端序号Seq,并将其值加1作为自己的确认号Ack的值;随后客户端进入ESTABLISHED阶段。
服务器收到来自客户端的“确认收到服务器数据”的TCP报文之后,明确了从服务器到客户端的数据传输是正常的。结束SYN-SENT阶段,进入ESTABLISHED阶段。
为什么不能两次握手
- client发送第一个请求①到server,但是由于网络不稳定,此次请求尚未到达server
- client发现server一直没有回复,再发一次请求②[第一次我握手,嗨,我要建立连接],第二个请求顺利到达server
- server和client进行第二次握手[好的,你建立吧].
- client和server进行第三次握手[那好,我真的建立]
- 此时第一次请求慢吞吞的到达server了.[syn=1,seq=x],server会认为是一个新的请求过来了.
- server和client想要进行第二次握手ack=x+1[确认号]
- client分析ack不是自己的,直接忽略此次来自于server端握手.
- server就会一直处于等待状态.
http状态码
- 200 - 请求成功
- 301 - 资源(网页等)被永久转移到其它URL
- 404 - 请求的资源(网页等)不存在
- 500 - 内部服务器错误
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
三大作用域
- request作用域 - HttpServletRequest,一次请求,一次响应.
- session作用域 - HttpSession - 一次会话期间,浏览器开启,浏览器关闭
- application作用域 - ServletContext - 服务器开启 - 服务器关闭 - 整个应用期间
HttpServletRequest和HttpServletResponse
HttpServletRequest
extends javax.servlet. ServletRequest[I]
所有的请求的信息都被封装到了HttpServletRequest对象中HttpServletResponse
extends javax.servlet. ServletResponse[I]
所有的响应给客户端的信息全部封装到这个对象中了.
Filter和Intecepor
Filter有如下几个用处。
- 在HttpServletRequest到达Servlet之前,拦截客户的HttpServletRequest。
- 根据需要检查HttpServletRequest,也可以修改HttpServletRequest头和数据。
- 在HttpServletResponse到达客户端之前,拦截HttpServletResponse。
- 根据需要检查HttpServletResponse,也可以修改HttpServletResponse头和数据。
拦截器,在AOP(Aspect-Oriented Programming)中用于在某个方法或字段被访问之前,进行拦截,然后在之前或之后加入某些操作。拦截是AOP的一种实现策略。
- Filter是基于函数回调的,而Interceptor则是基于Java反射的。
- Filter依赖于Servlet容器,而Interceptor不依赖于Servlet容器。
- Filter对几乎所有的请求起作用,而Interceptor只能对action请求起作用。
- Interceptor可以访问Action的上下文,值栈里的对象,而Filter不能。
- 在action的生命周期里,Interceptor可以被多次调用,而Filter只能在容器初始化时调用一次。
监听器
Listener监听器就是一个实现特定接口的普通Java程序,这个程序专门用于监听一个java对象的方法调用或属性改变,当被监听对象发生上述事件后,监听器某个方法将立即被执行。
监听器Listener就是在application,session,request三个对象创建、销毁或者往其中添加修改删除属性时自动执行代码的功能组件。
Listener是Servlet的监听器,可以监听客户端的请求,服务端的操作等。
Listener实现了javax.servlet.ServletContextListener 接口的服务器端程序,它也是随web应用的启动而启动,只初始化一次,随web应用的停止而销毁。主要作用是:做一些初始化的内容添加工作、设置一些基本的内容、比如一些参数或者是一些固定的对象等等.
九大内置对象
- out(JspWriter):等同与response.getWriter(),用来向客户端发送文本数据;
- config(ServletConfig):对应“真身”中的ServletConfig;
- page(当前JSP的真身类型):当前JSP页面的“this”,即当前对象;
- pageContext(PageContext):页面上下文对象,它是最后一个没讲的域对象;
- exception(Throwable):只有在错误页面中可以使用这个对象;
- request(HttpServletRequest):即HttpServletRequest类的对象;
- response(HttpServletResponse):即HttpServletResponse类的对象;
- application(ServletContext):即ServletContext类的对象;
- session(HttpSession):即HttpSession类的对象






